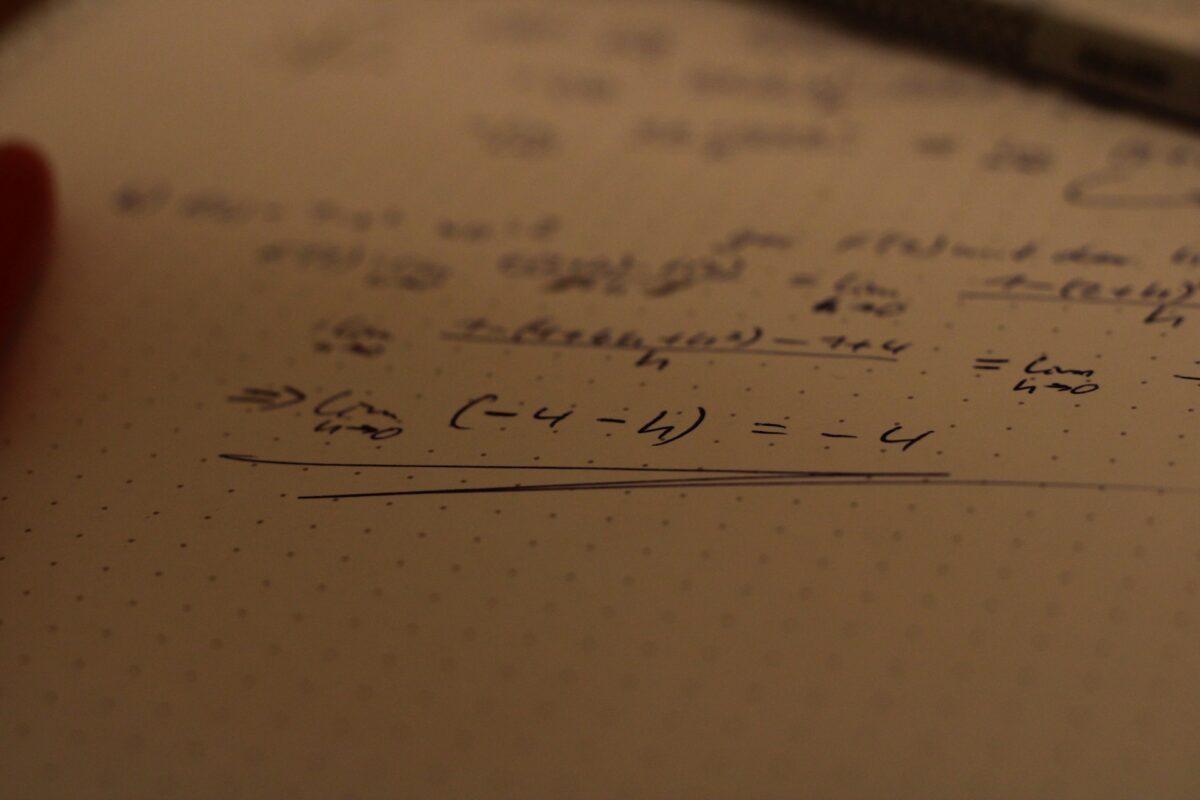Welcome to another statistics article, probably the most frustrating category for me to prepare. Why? Because there’s no code, no practice problems… just plain old text. However, today we have a special guest, and it happens to be the favorite of all machine learning models: Correlation. Machine learning models are essentially algorithms designed to predict […]